This is the drafted solution to ingest nasa web access logs, process and clean the data, store into a data warehouse for further analysis.
It is implemented with GCP products, including Pub/Sub, Dataflow, BigQuery.
Introdcution
Inspired by the article Scalable Log Analytics with Apache Spark — A Comprehensive Case-Study to process nasa logs with Apache Spark, I implement a drafted solution with some products on GCP. This can be reframed as a typical data streaming process pipeline. More concretely, we have web access logs which are generated continuously to ingest to the pipeline, then we need to parse each log into to different fields, finally it is required to store into a database or data warehouse for further analysis (i.e. visualisation, hourly/daily reports, anomaly detection, etc.). GCP provides a variety of products which are well fit for this use case. Let us dive into the details.
Solution Architecture
We will follow the typical data processing pipeline from data ingestion, processing and transforming, to storage and analysing.
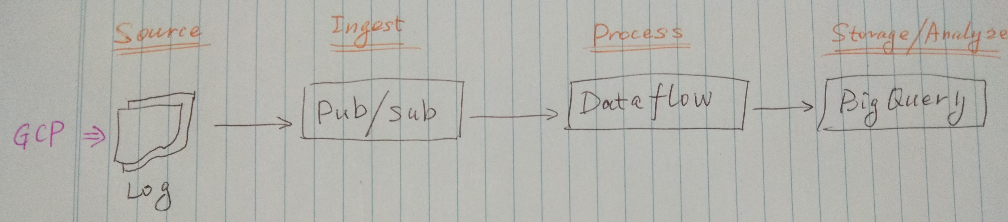
Data Ingestion
For data ingestion, due to the nature of continuous log generation, as a results we will think of Cloud Pub/Sub. It is a fully-managed, auto scaling message delivery system. It makes the pipeline more robust by decoupling senders and receivers of event data. The message will be retained for 7 days. It guarantees to deliver each published message at least once for every subscription.
Data Processing
Since the web access log is with semi-structured format, we can’t import the log into a database directly. Cloud Dataflow is right tool for data processing and transformation. It uses Apache Beam SDK which is a unified programming model that enables you to develop both batch and streaming pipelines. It also has a rich set of connectors to different data sources.
Data Storage and Analysing
Once the data is transformed into structured format, it can be stored into a database or data warehouse for further analysis. BigQuery is the data warehouse product on GCP. BigQuery can run complex queries on terabytes or even petabytes of data in blazing-fast speed with standard SQL. Behind the scene, BigQuery is leveraging Google’s own technologies like Borg, the cluster manager and resource scheduler; Dremel, the query engine; Colossus, the distributed file system; and Jupiter, the network which can deliver 1 Petabit/sec of total bisection bandwidth.
Solution Build and Implementation
Setup a GCP project
Setting up a project on GCP can be easily completed via the console. For this task, it involves creating a service account, a topic and subscription to receive and deliver the event data in Pub/Sub, a dataset and a table to store and analyse the data in BigQuery.
Send data to Pub/Sub
The access log is with The Common Logfile Format, some sample data look like below.
1
2
3
4
199.72.81.55 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245
unicomp6.unicomp.net - - [01/Jul/1995:00:00:06 -0400] "GET /shuttle/countdown/ HTTP/1.0" 200 3985
199.120.110.21 - - [01/Jul/1995:00:00:09 -0400] "GET /shuttle/missions/sts-73/mission-sts-73.html HTTP/1.0" 200 4085
burger.letters.com - - [01/Jul/1995:00:00:11 -0400] "GET /shuttle/countdown/liftoff.html HTTP/1.0" 304 0
With Google Cloud API, it is pretty easy to write a Python script to send the access log to Pub/Sub continuously in real-time.
1
2
3
python send_nasa_log.py --input ./data/access_log_sample --project $GOOGLE_CLOUD_PROJECT --topic nasa_log
INFO: Reusing pub/sub topic nasa_log
INFO: Sending 200 events to projects/<GOOGLE_CLOUD_PROJECT>/topics/nasa_log
Imagine you have a website and the customers access all over the world. You can ingest the event data from any place to Pub/Sub, no need to worry about setting up the infrastructure, servers and the process frameworks.
Parse data with Dataflow
Once the data is in the Pub/Sub, we can use Dataflow to pull the published message from the subscription. We need to parse them into fields before the data can be written to BigQuery. It is also required to perform data cleasing and transformation.
It is commonly to use regular expression to extract the patterns from the semi-structured data and to filter out those mal-formated records.
Below is the function to parse the record into relevant fields.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def process(self, element):
"""
Parse each record into relevant fields and return as a dict
"""
pattern = rb'(^\S+?)\s.+?\[(.+)\]\s+"(.+?)\s(\S+)\s*(.*)"\s(\d+)\s(.+)'
match = re.match(pattern, element)
if match is not None:
res = {}
res['host'] = match.group(1).decode('utf-8')
res['utc_timestamp'] = parse_timestamp(match.group(2).decode('utf-8'))
res['action'] = match.group(3).decode('utf-8')
res['uri'] = match.group(4).decode('utf-8')
res['protocol'] = match.group(5).decode('utf-8')
res['status'] = match.group(6).decode('utf-8')
res['size'] = str_to_int(match.group(7).decode('utf-8'))
yield res
else:
return
We also need to convert the original timestamp in the records which looks like [01/Jul/1995:00:03:15 -0400] into UTC before storing into BigQuery. Here is the snippet.
1
2
3
4
5
6
def parse_timestamp(str_ts):
"""
Convert Common Log time format into a Python datetime object in UTC
"""
local_ts = datetime.strptime(str_ts, '%d/%b/%Y:%H:%M:%S %z')
return local_ts.astimezone(pytz.utc).isoformat()
Here is the graph when Dataflow is running.
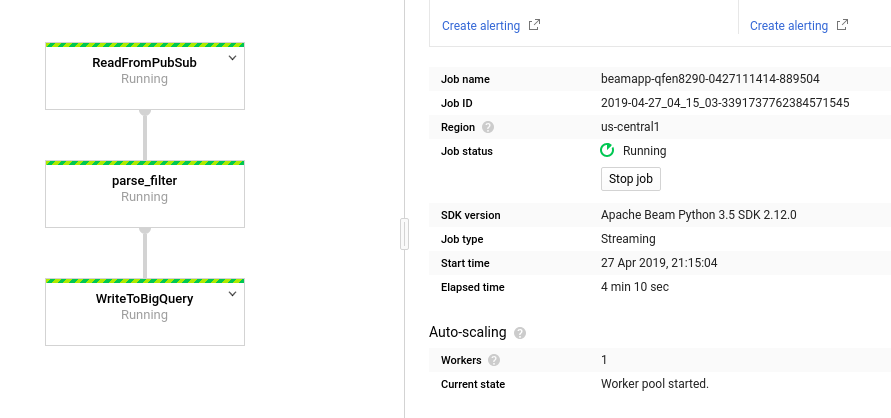
Store and Analyse data with BigQuery
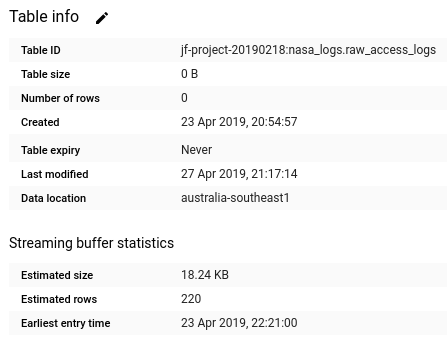
With Dataflow, the data are transferred into structured fields and ingested into BigQuery. It shows the data are streaming into BigQuery in almost real-time once they are processed.
We can immediately query the data in BigQuery.
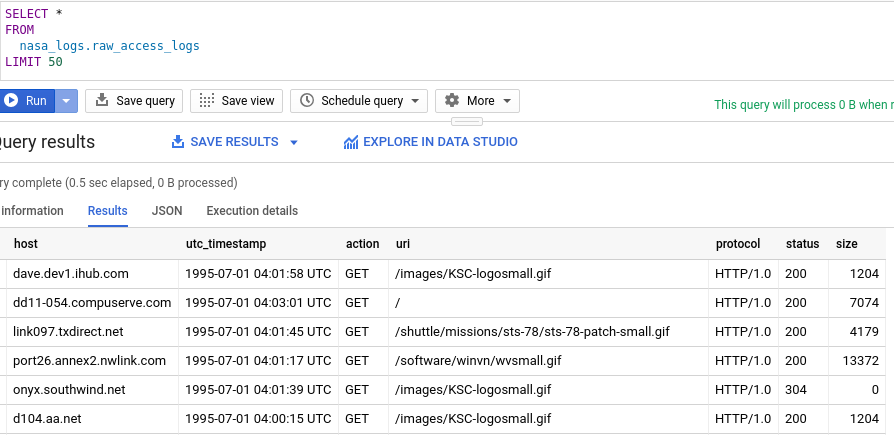
Then we can use BigQuery to run complex queries to derive insights from the data and generate various BI reports. Moreover, we can even run machine learning models on top of BigQuery, for example, we can train a regression model to predict the traffic of the website for next week.
Conclusion
With Cloud Computing, we don’t need to build from scratch for the underlying infrastructure, Linux servers and the data processing frameworks. This kind of time-consuming overheads are now replaced with a few mouse clicks. We can more focus on the application and data insights. This solution prototype can be built and implemented within a day. It can be easily expanded according to the complexity of business requirements. More importantly, it is production ready from day one.
To be continued…
As I have been working a lot with Apache Hadoop/Spark ecosystem, I will come up with the equivalant solution with open-source frameworks.