I have written a post about using Apache Spark to process multiple XML files and convert into tabular format. In this post, we are going to use AWS Lambda, S3 and Athena to achieve the same results.
With this solution, we don’t need to provision and maintain any infrastructure and it can scale up or down automatically. We just put more focus on the code to implement the business logic. It dramatically reduces the time from prototype to productionisation. That is the beauty of serverless!
Solution
In a nutshell, a Lambda function is trigger to parse the XML content once an XML file is landed in the S3 bucket, then we can use Athena to query the processed data via SQL.
Step 1: Define a Lambda function to process XML files
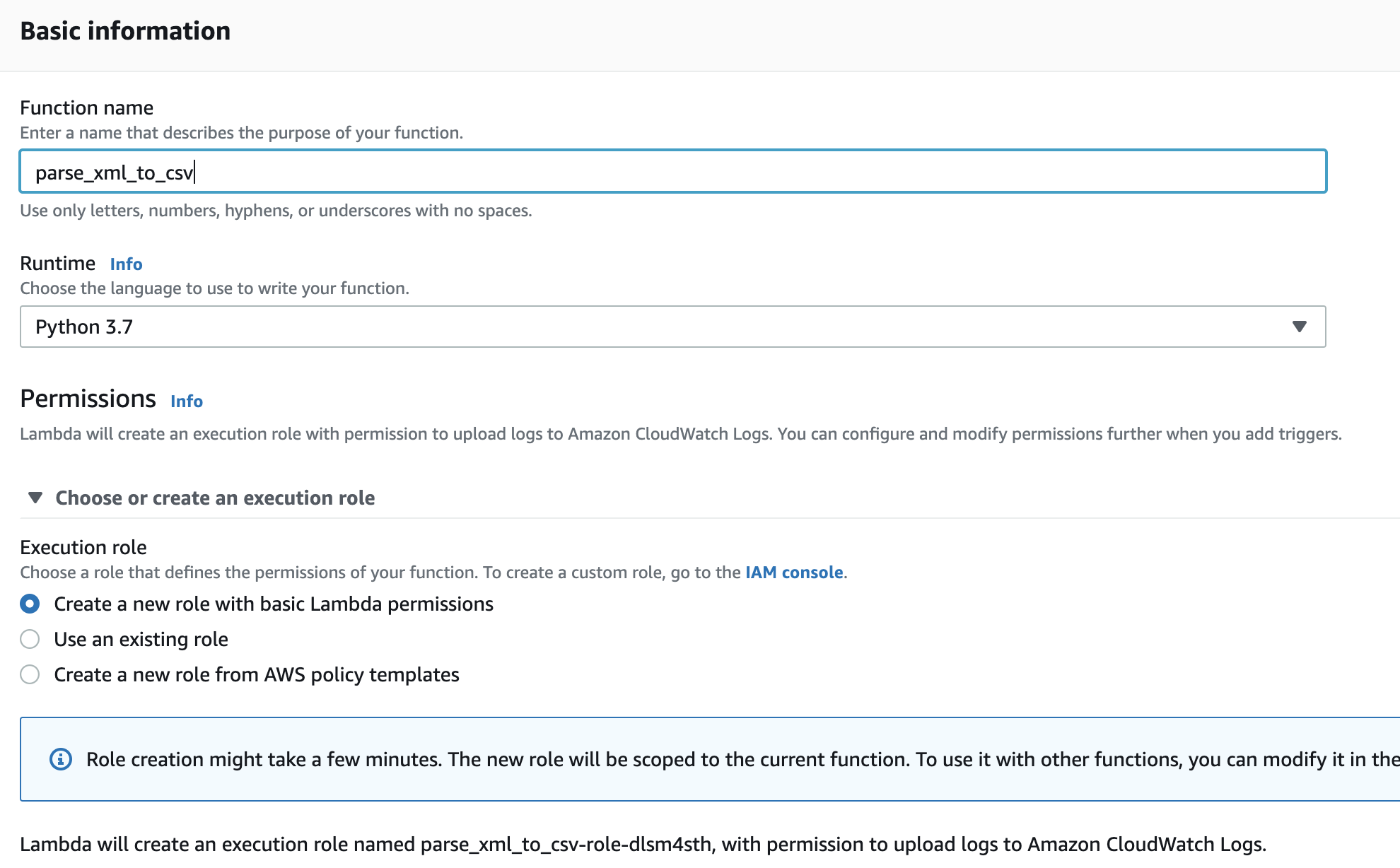

Step 2: Enable S3 bucket to trigger the Lambda function
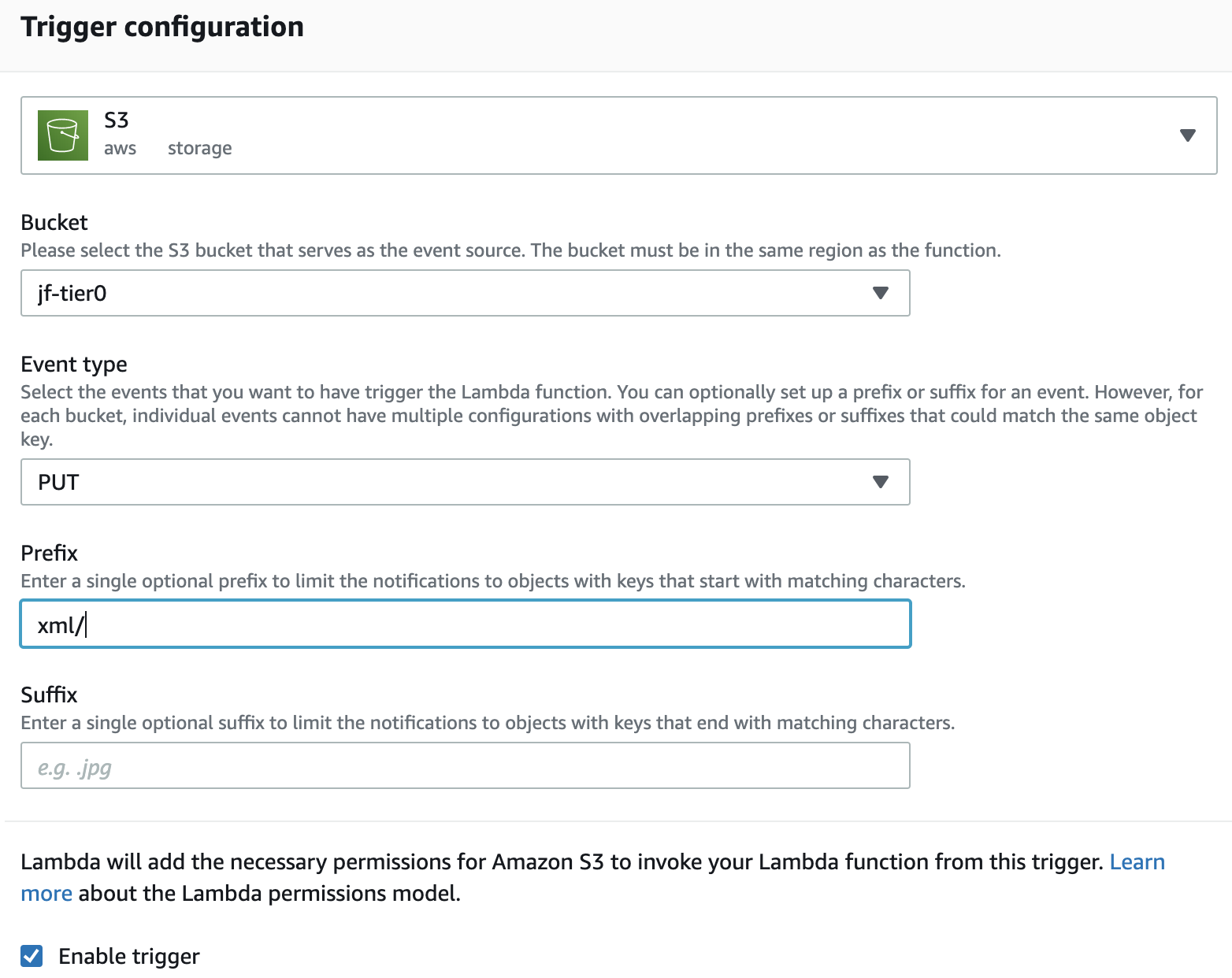
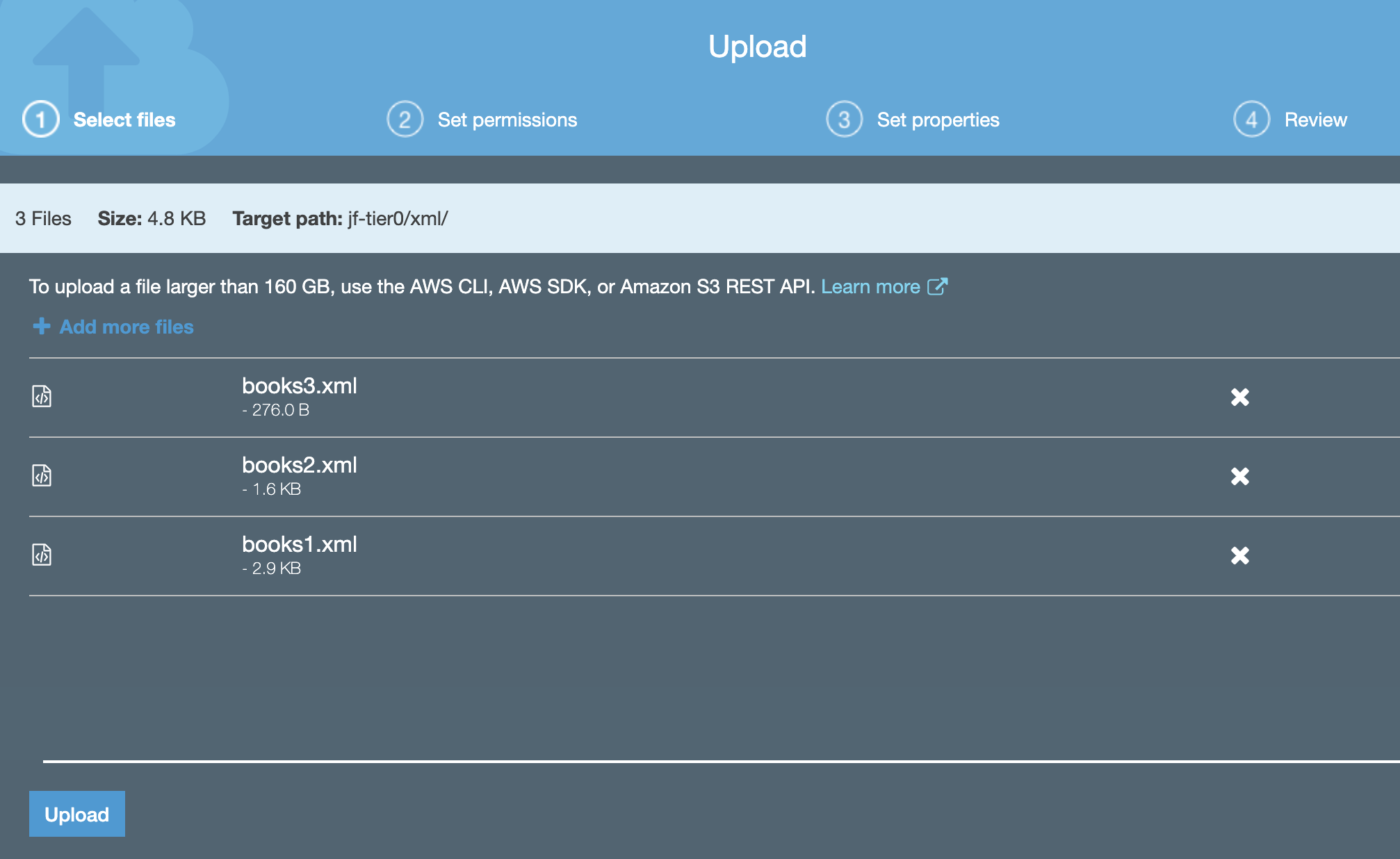
Step 3: Put XML files to the S3 bucket
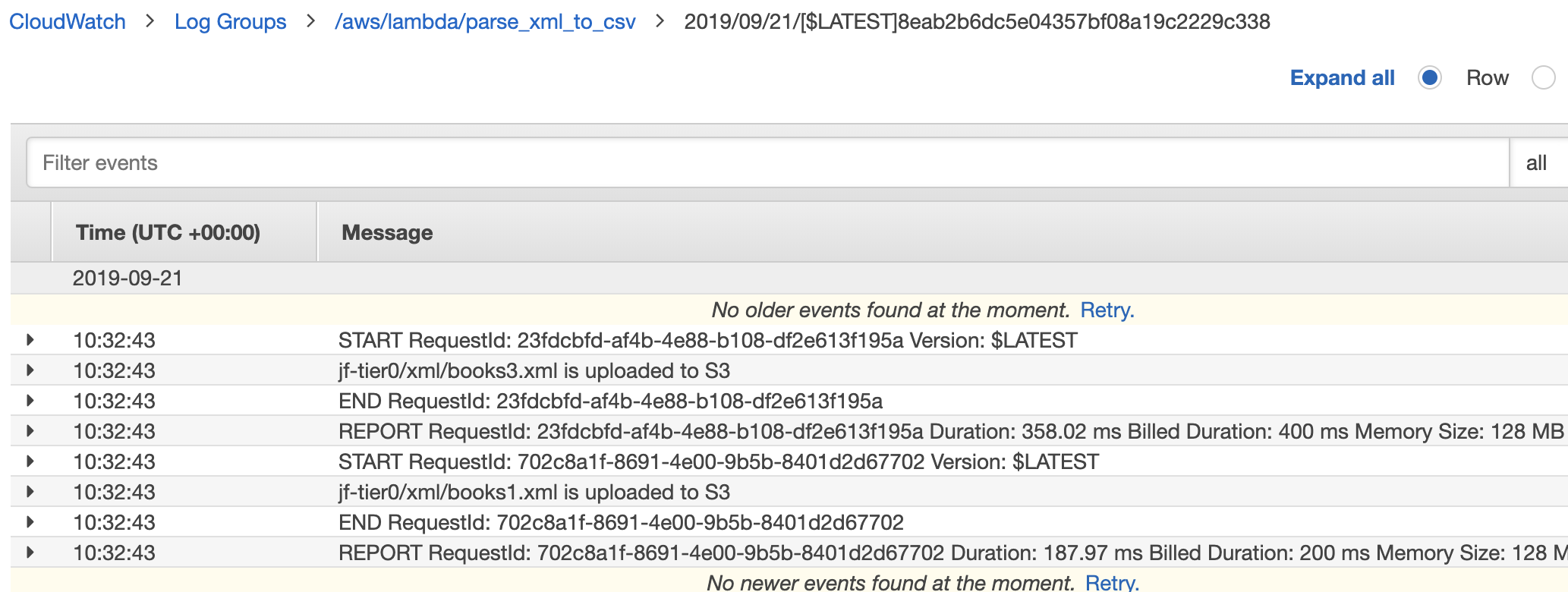
Once the files are uploaded, we can monitor the logs via CloudWatch that the Lambda function is invoked to process the XML file and save the processed data to to targeted bucket.
Step 4: Create data catelog with Glue and query the data via Athena
We can use Glue to run a crawler over the processed csv files to create a new table which behind the scene generates a data catelog metadata. Then we can run SQL in Athena to check the data.
Conclusion
Through this simple example, we have already used the essential services for data processing and analytics provided by AWS, namely, Lambda Function, AWS Glue, Athena.