Here is a list of AWS services with which a data engineer such as me is commonly interacting during the daily tasks.
Amazon S3
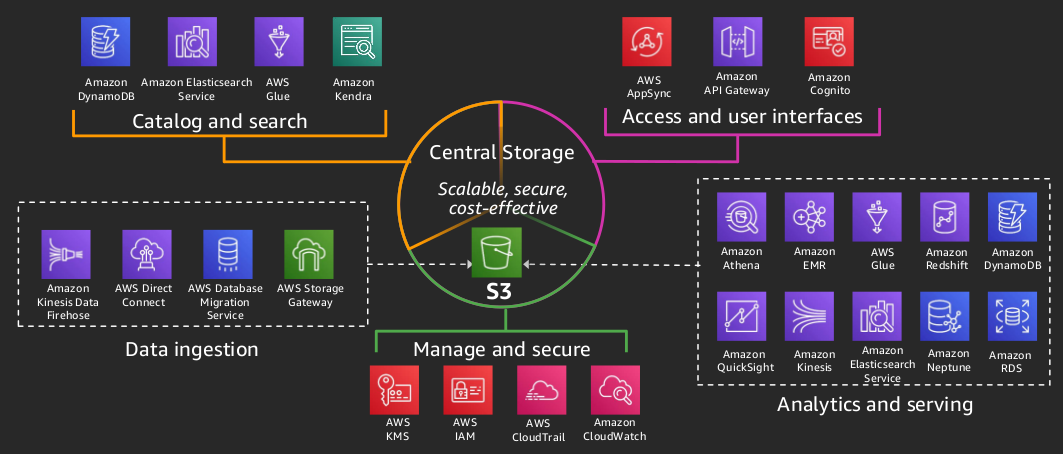
A data engineer is working with all kinds of data everyday. First and foremost, we need a place to store the data. Prior to the cloud, this is normally the local disks in the PC or network storage in a data center. In AWS, this is S3, the object storage service. S3 is the first service provided by AWS. Literally, we can put any amount of data to S3, no need to worry about the capacity. S3 is designed with scalability, data availability, security, and 11 9’s durability.
S3 is also the core component in AWS data lake architecture as a centralized repository that allows you to store all the structured and unstructured data at any scale.
AWS Glue
Once the data is available in S3, we want to know the content of the data. Glue Crawlers can scan the data and store the associated metadata (i.e. table definition and schema) in the AWS Glue Data Catalog using pre-built classifiers for many popular source formats and data types, including JSON, CSV, Parquet, and more.
We can even run the crawlers with a schedule. This is helpful in the scenario that the data source is changed (i.e. new columns are added) so that the schema can be updated automatically.
We can perform ETL work with PySpark scripts using Glue job. We just need to provide the script specifying data source and target and the business logic to transform the data. The script is executed in an Apache Spark environment managed by AWS Glue. However, I personally prefer to run Spark job on EMR which I can fully manage the underlying cluster with fine-grained performance tuning.
AWS Athena
After we have the metadata in the Data Catalog, we can start to get some insight from the data with Athena.
Amazon Athena is an interactive service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is based on presto. Athena is serverless, and no infrastructure to manage, and we pay only for the amount of data the query scans ($5 per TB). It is wise to have the underlying data stored as snappy or gz Parquet so that we can gain the performance of query while lowering the cost. We can normally get the results in secords when querying GBs of data in Parquet format with good partitions.
Amazon QuickSight
Visualization is much more intuitive when presenting the data analytics and insights to the business and stakeholders.
Amazon QuickSight allows us easily create and publish interactive dashboards which can be accessed from any device, sent via emails, and embedded into applications and websites.
Amazon QuickSight is a managed, serverless, business intelligence service. The data sources include native integration to AWS services such as RedShift, S3.
AWS Lambda
It is not unusual that we can’t directly consume the raw data sources. In case the size of raw data is not that big, we can use AWS Lambda to parse and transform data.
AWS Lambda lets us run code without provisioning or managing servers. We pay only for the compute time consumed. By default, Lambda provide rich run-times with different programming languages, such as Python, Go, Java, NodeJS. We can also provide customised run-time with extra packages.
If it is required to fetch the raw data, Lambda is very handy in such scenario. We can create a Lambda function to hit an API endpoint, get the result, parse the data and save to S3 or DynamoDB. We can easily set the schedule to invoke Lambda with CloudWatch Event Rule.
Another common way is to use Lambda as a glue to invoke other AWS services. Here is an example I have worked on. When a large raw data file is uploaded to S3, a Lambda function is triggered to invoke a Step Function with proper input parameters. Inside the Step Function, a Lambda is invoked to create an EMR cluster to run Spark jobs to process the data, another Lambda checks the EMR status periodically. After the Spark jobs are finished, a Lambda runs Athena query to update the partition of the destination table. In case of any failure during the execution, a Lambda invokes SNS to send the email notification.
AWS EMR
With EMR, we can spin up an ephemeral cluster to perform any Spark, Hive, or Flink jobs. It gives us the total freedom to specify the underlying EC2 instances, to provide cluster configuration, to define the dependencies.
It seems very tedious to define an EMR cluster in the beginning. We need to define a VPC, subnets, security groups, IAM roles, EC2 instance type, etc.. All these are on-off things which can be done with CloudFormation. In return, We can archive fine-grained performance tuning against the running jobs. With EC2 spot instances, the cost will be much cheaper.
Amazon Kinesis
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so we can get timely insights and react quickly to new information. It is fully managed, scalable, real-time streaming data process platfrom. It includes Kinesis Data Streams which is similar to Apache Kafka; Kinesis Data Firehose which can send the streaming data to AWS services like S3, RedShift; Kinesis Data Analytics which allows us to write SQL code and do schema transformation.
Amazon CloudWatch
CloudWatch is the centralised log service where we can find the logs for the services we run. It is very helpful to log the debug information during development. We can also use CloudWatch Events to schedule the services we want to invoke in a given period.
Amazon DynamoDB
DynamoDB is a key-value and document database that delivers sub-second performance at any scale. It can be used to store semi-structure data with a unique key. We can also use DynamoDB to keep track the status of other services like Step Functions to avoid race condition.
AWS Step Functions
AWS Step Functions lets us coordinate multiple AWS services into serverless workflows. Using Step Functions, we can design and run workflows that stitch together services, such as AWS Lambda, Athena, and EMR, into feature-rich applications.
It is used a JSON-based language describe state machines. It provides rich states to suite different requirements of workflows, such as Choice to branch based on the output of previous task, error handling, running multiple tasks in parallel.
AWS CloudFormation
AWS CloudFormation allows us to provision all the resources needed for the applications in an automated and secure manner. We can define a template with all the resources required for a task, such as S3 buckets, Athena tables, Lambda Functions, Step Functions, IAM roles, etc.. With a few clicks, the stack can be deployed in a few minutes. If rollback is required for any reason, just delete the stack without affecting all the other applications.
AWS IAM
Security is always a prominent concern especially when dealing with sensitive data. We can use IAM to create a tailored role with the principle of least privilege to each service we use in AWS.
AWS Lake Formation
With Lake Formation, it provides the flexibility to fine-grain the security control of the access to the data, even on a specific column. This service just came out last year. I haven’t got the opportunity to play around yet.
Conclusion
I only cover some most commonly used AWS services from a data engineer perspective. Definitely there are more services a data engineer is likely to use than those ones mentioned above. For example, RedShift is the Data Warehouse solution which I haven’t used much because of higher cost. We may use AWS Batch or ECS to run some jobs with container. The good news is AWS is never stopping with innovation so that data engineers can benefit from using more efficient and powerful services.