There is an introductory article of AWS services which can help to build data lake in WeChat. I translated to English as I found it quite intuitive.
Long time ago, when data was limited, people could remembered them without noting down, or just put knots in the ropes.
 Then database was invented for the sake of more efficient recording and processing. The core of database was to query, insert, delete and update records for online transactions. For example, you spend with your bank card, the backend database is required to record this transaction in real time, and update the balance of your account.
Then database was invented for the sake of more efficient recording and processing. The core of database was to query, insert, delete and update records for online transactions. For example, you spend with your bank card, the backend database is required to record this transaction in real time, and update the balance of your account.

As the time goes by, the amount of data are kept increasing. The database is not only needed to cater for online transaction processing, it is required to provide online analytical processing. However, the traditional database can only support high frequent and fast IO requests. It is hard to run complex queries to analyze large amount of data.
Hence, people came up data processing based on the database. More precisely, data are extracted, transformed and loaded (ETL) into another system which is called data warehouse. The main purpose of data warehouse is used for business intellegence (BI), dashboard, data analytics and insights, etc.

Quick recap, database is used for OLTP, which captures, stores, and processes data from transactions in real time. data warehouse is used for OLAP, which uses complex queries to analyze large amount of historical data from OLTP systems.


Data in both OLTP and OLAP systems are mainly structured data. Together with these two systems, most companies can deal with the real time transactional process and analytical process.
However, people is never satisfied with status quo. The types of data become more and more. For example, semi-structured data such as csv, XML, JSON; un-structured data such as text, mail, image, video. Companies want to derive values from these Big Data. They want to store them and utilize them properly.

How can we deal with such complicated data with various formats? How about putting all of them into a lake!!
 This is the prototype of Data Lake which serves as a central repository of all kinds of heterogeneous data.
This is the prototype of Data Lake which serves as a central repository of all kinds of heterogeneous data.
Why not Data River? We need to keep the data. We can’t let go the data along with the flow.
Why not Data Pool? Like a swimming pool? It is not big enough for the growing data.
Why not Data Sea? We need a boundary for the data. They can’t flow out to other sea freely.
Then it comes to the challenges of data lake.
- Where to dig the lake? The storage aspect of data lake.
- How to get the water flow in? The ETL process of data lake.
- How to serve for good with the lake? The analytics of data lake.
With various AWS services, data lake can be built with much less effort.
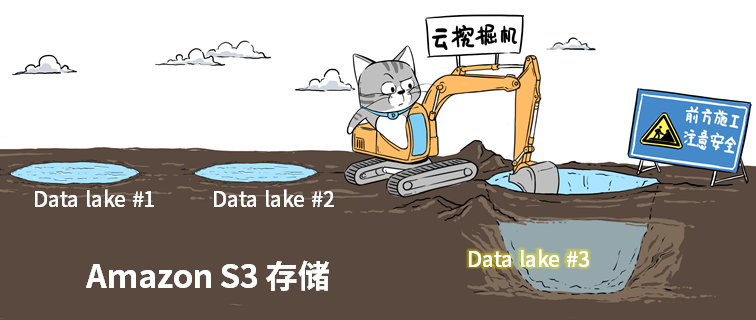
Storage
First and foremost, data lake is an architect of storage of data. So it is natually to think of S3 as the foundation of data lake. Companies can quickly dig up a just-fit “lake” which is scalable and shrinkable, only paid for the amount of water (data).
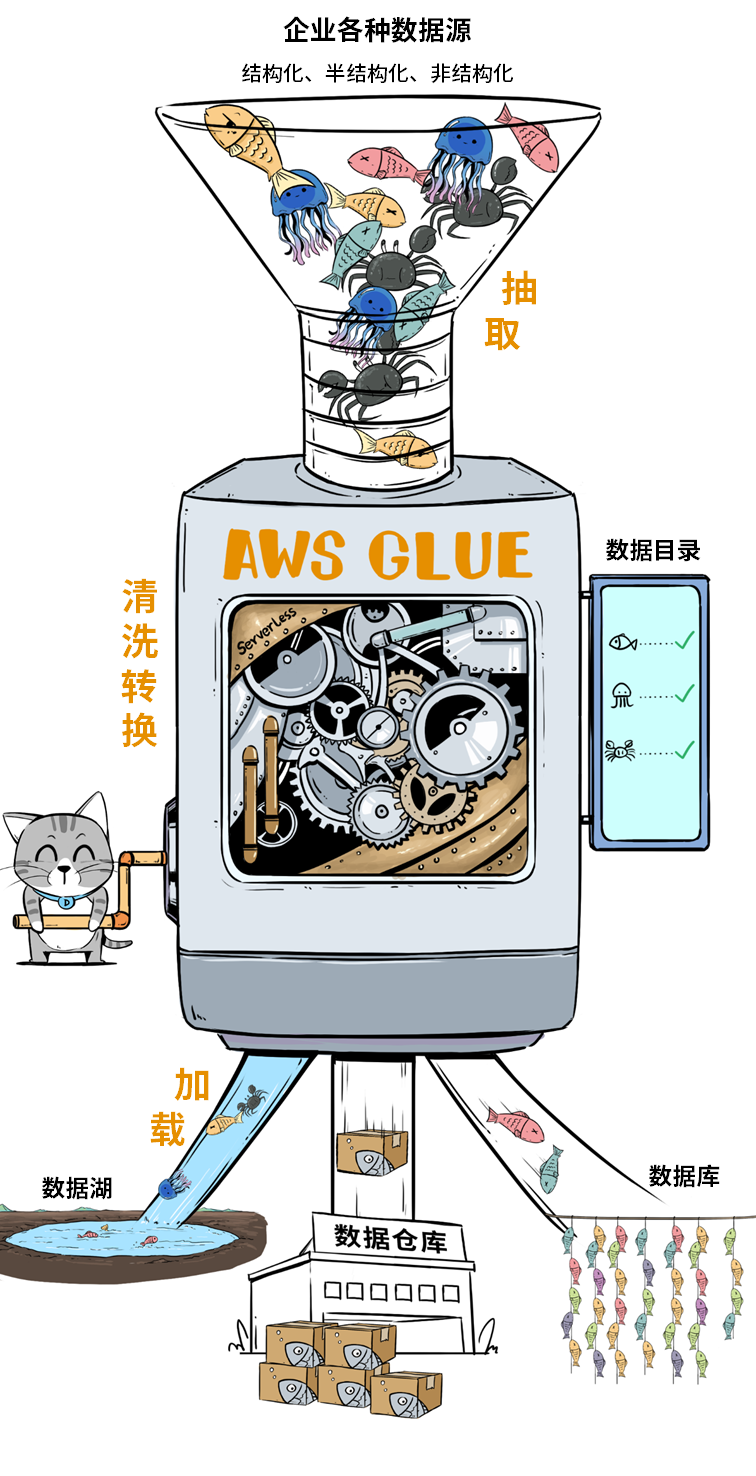
ETL
Then it is the process to get all the heterogeneous data into the lake. AWS Glue comes into spot for this part. It has a component called Crawler which can discover the metadata (schema) of the data. Glue ETL jobs run Apache Spark to process and load the data either via our customised code or visual ETL code generation. Furthermore, Glue is a serverless service which we don’t need to manage the underlying cluster.
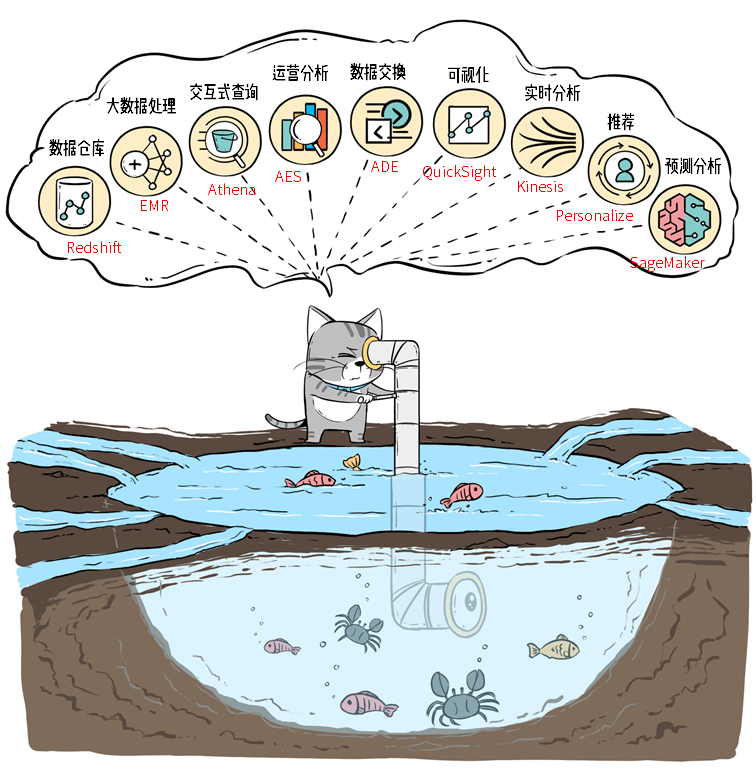
Analytics
Athena lets us to run standard SQL queries over the data stored in S3. It is also serverless and we can run the query and get the data insights within a short time no matter it is hundreds of MB or GB of data. It is billed by the amount of data which the query scans.

Other services
There are other services to meet the different requirements. EMR is for big data processing, Kinesis is for streaming data processing, QickSight is for data visualisation, etc..
References
- Original article - 数据湖这个大坑,是怎么挖的?
- Data Lake vs Data Warehouse
Image by Free-Photos from Pixabay