This is part three of the notes of the course AWS Machine Learning Foundations on Udacity.
Machine Learning Techniques
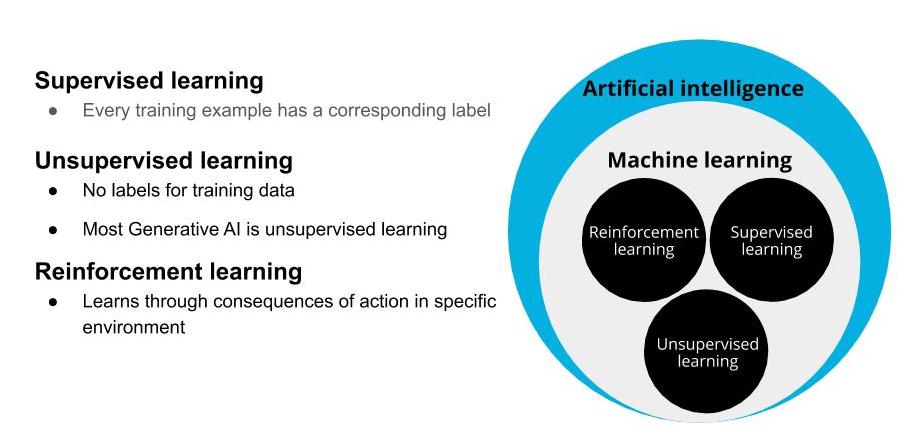
Supervised Learning: Models are presented wit input data and the desired results. The model will then attempt to learn rules that map the input data to the desired results.
Unsupervised Learning: Models are presented with datasets that have no labels or predefined patterns, and the model will attempt to infer the underlying structures from the dataset. Generative AI is a type of unsupervised learning.
Reinforcement learning: The model or agent will interact with a dynamic world to achieve a certain goal. The dynamic world will reward or punish the agent based on its actions. Overtime, the agent will learn to navigate the dynamic world and accomplish its goal(s) based on the rewards and punishments that it has received.
Generative AI
Generative AI is one of the biggest recent advancements in artificial intelligence technology because of its ability to create something new. It opens the door to an entire world of possibilities for human and computer creativity, with practical applications emerging across industries, from turning sketches into images for accelerated product development, to improving computer-aided design of complex objects. It takes two neural networks against each other to produce new and original digital works based on sample inputs.
AWS Composer and Generative AI
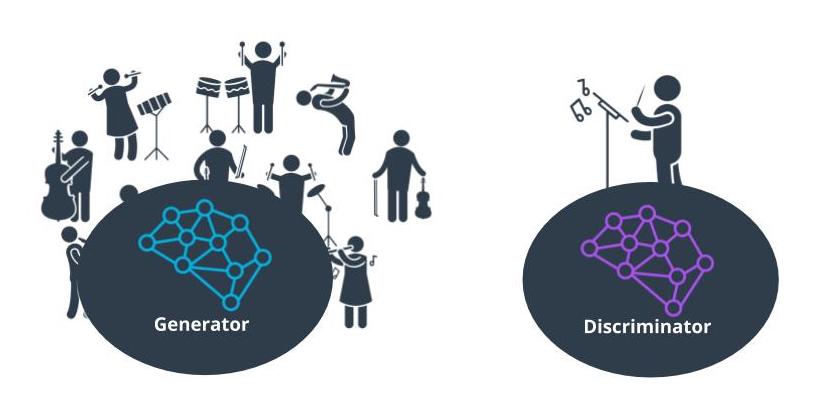
AWS Deep Composer uses Generative AI, or specifically Generative Adversarial Networks (GANs), to generate music. GANs pit 2 networks, a generator and a discriminator, against each other to generate new content.
The best way we’ve found to explain this is to use the metaphor of an orchestra and conductor. In this context, the generator is like the orchestra and the discriminator is like the conductor. The orchestra plays and generates the music. The conductor judges the music created by the orchestra and coaches the orchestra to improve for future iterations. So an orchestra, trains, practices, and tries to generate music, and then the conductor coaches them to produced more polished music.
Generative adversarial networks
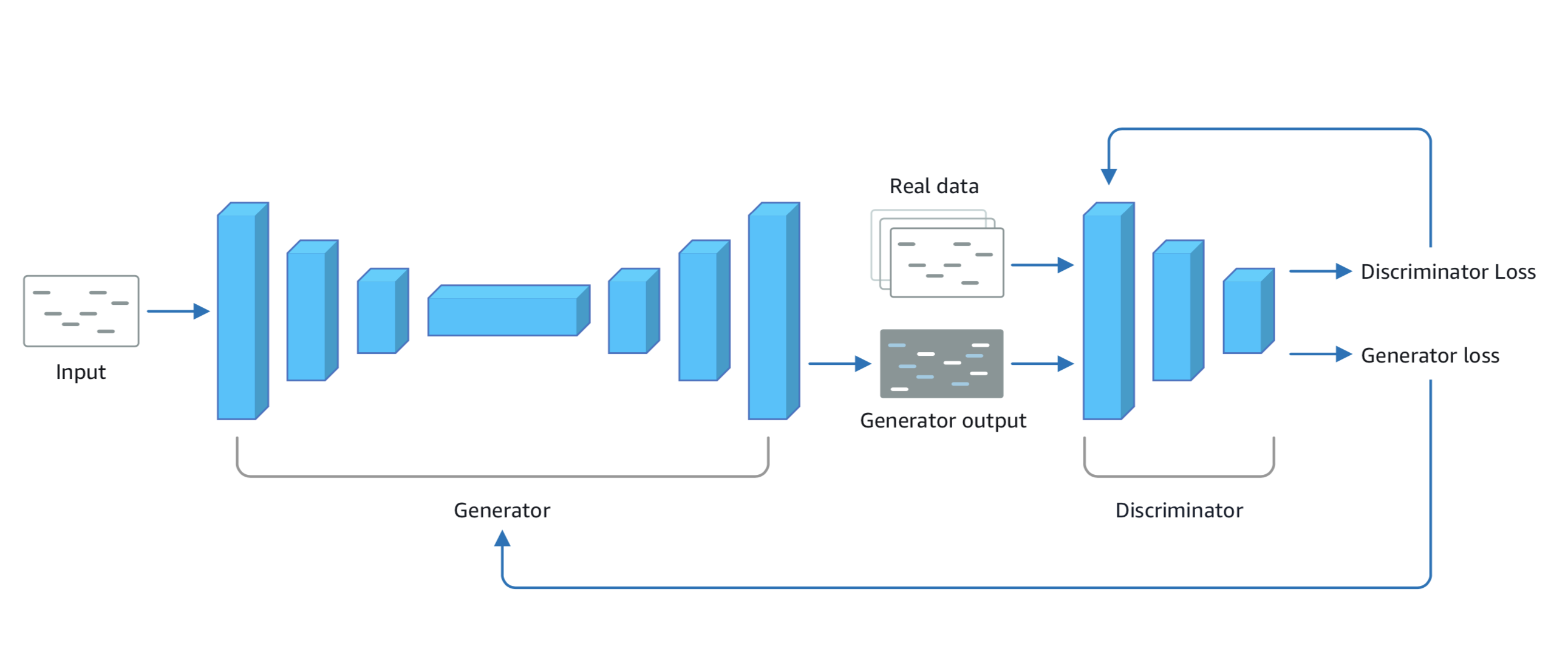
Generative Adversarial Networks (GANs) are a type of machine learning network in which two neural networks compete. One network is tasked with generating realistic-seeming content (unsupervised learning), while the other network is tasked with distinguishing the generated content against real data (supervised learning).
The generator within a GAN is a machine learning model that’s trained to produce realistic-seeming output.
The discriminator is another machine learning model which is trained to take an input and classify whether or not the input is real or generated.
Initially, the generator produces content samples based on random inputs. The discriminator looks for features (e.g. tempo) from the dataset it was trained on (e.g. Pop, Rock, Classical) in the content samples the generator created. It decides whether or not the content samples belong in the training set.
The generator and the discriminator are trained in alternating cycles such that the generator learns to produce more and more realistic data while the discriminator iteratively gets better at learning to differentiate real data from the newly created data.
The results of the discriminator’s judgements are used to train both models. The generator is trained to optimize for producing realistic content that the discriminator cannot distinguish from the real samples. Meanwhile, the discriminator is trained to increase its ability to detect generated content.
This back-and-forth behavior, where the two models are directly competing against each other, is the adversarial part of GANs.
AWS DeepComposer Workflow
- Use the AWS DeepComposer keyboard or play the virtual keyboard in the AWS DeepComposer console to input a melody.
- Use a model in the AWS DeepComposer console to generate an original musical composition. You can choose from jazz, rock, pop, symphony or Jonathan Coulton pre-trained models or you can also build your own custom genre model in Amazon SageMaker.
- Publish your tracks to SoundCloud or export MIDI files to your favorite Digital Audio Workstation (like Garage Band) and get even more creative.
AWS DeepComposer Under The Hood
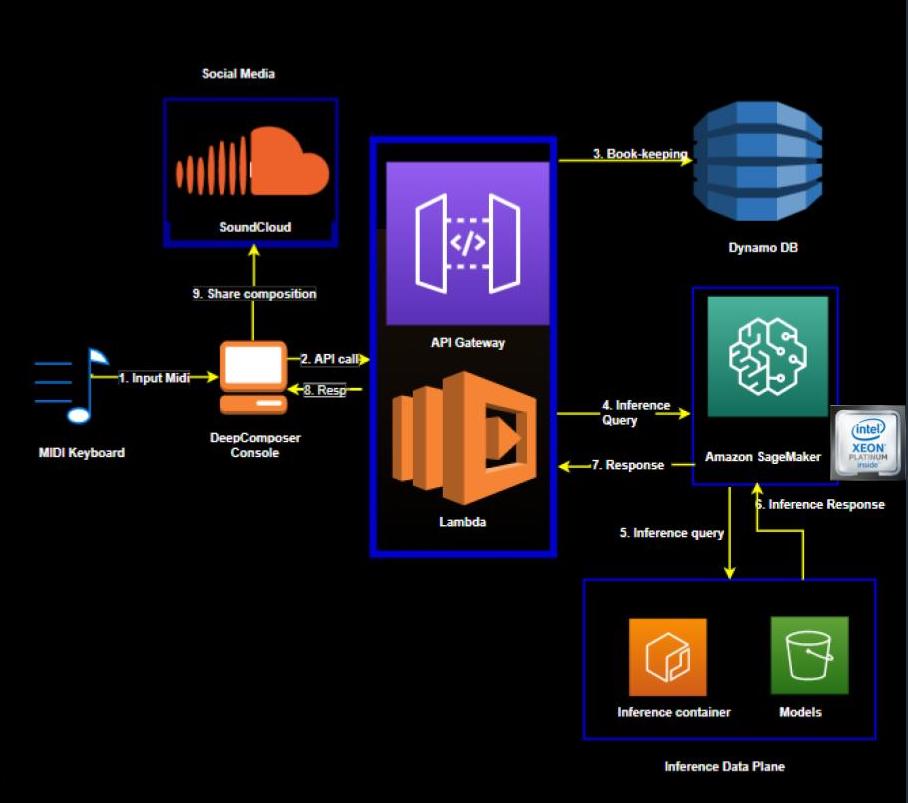
- Input melody captured on the AWS DeepComposer console
- Console makes a backend call to AWS DeepComposer APIs that triggers an execution Lambda.
- Book-keeping is recorded in Dynamo DB.
- The execution Lambda performs an inference query to SageMaker which hosts the model and the training inference container.
- The query is run on the Generative AI model.
- The model generates a composition.
- The generated composition is returned.
- The user can hear the composition in the console.
- The user can share the composition to SoundCloud.
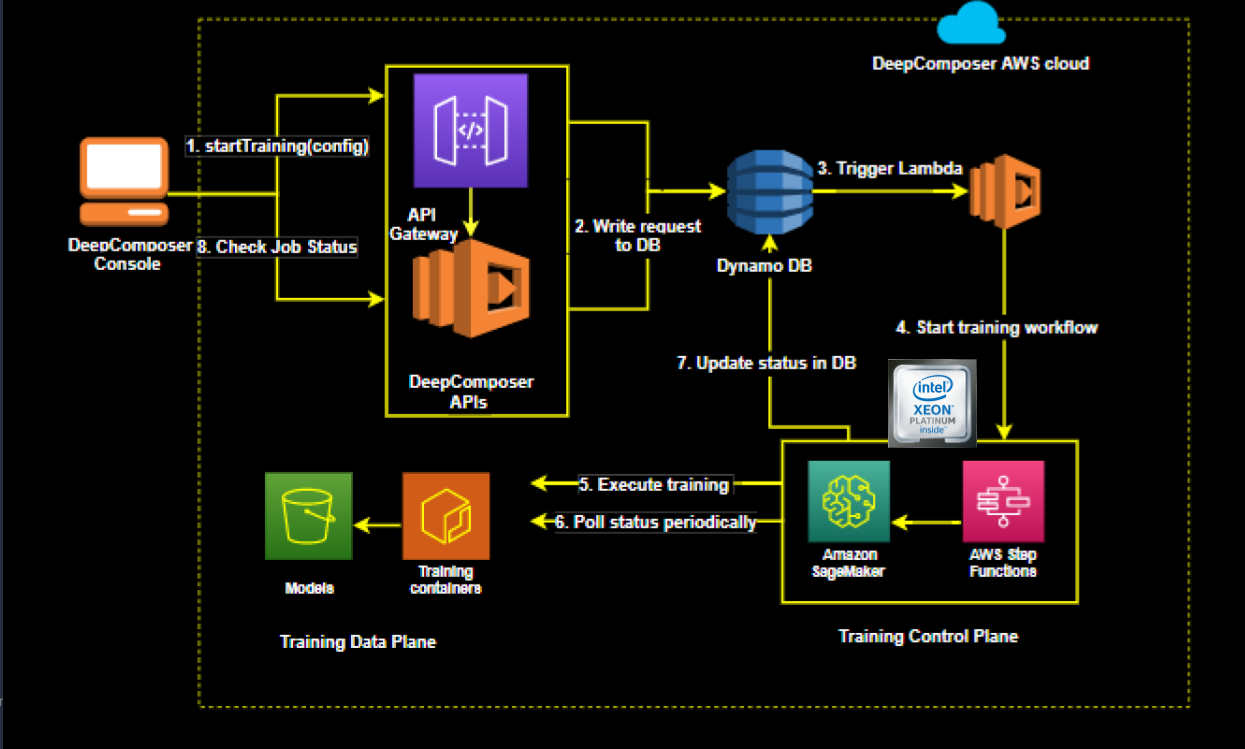
Training architecture
- User launch a training job from the AWS DeepComposer console by selecting hyperparameters and data set filtering tags
- The backend consists of an API Layer (API gateway and lambda) write request to DynamoDB
- Triggers a lambda function that starts the training workflow
- It then uses AWS Step Funcitons to launch the training job on Amazon SageMaker
- Status is continually monitored and updated to DynamoDB
- The console continues to pull the backend for the status of the training job and update the results live so users can see how the model is learning
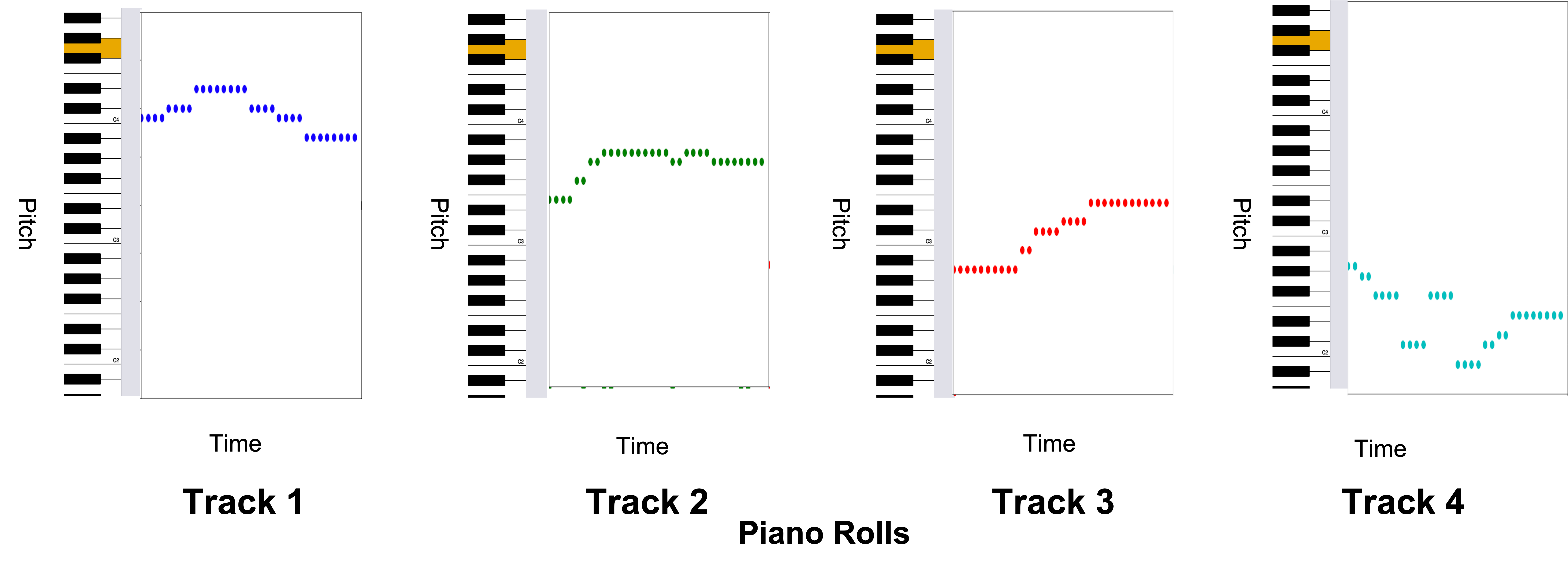
How U-Net based model interprets music
In AWS DeepComposer, we represent music as a two-dimensional matrix (also referred to as a piano roll) with “time” on the horizontal axis and “pitch” on the vertical axis. You might notice this representation looks similar to an image. A one or zero in any particular cell in this grid indicates if a note was played or not at that time for that pitch.
Challenges with GANs
- Clean datasets are hard to obtain
- Not all melodies sound good in all genres
- Convergence in GAN is tricky – it can be fleeting rather than being a stable state
- Complexity in defining meaningful quantitive metrics to measure the quality of music created
Model Architecture
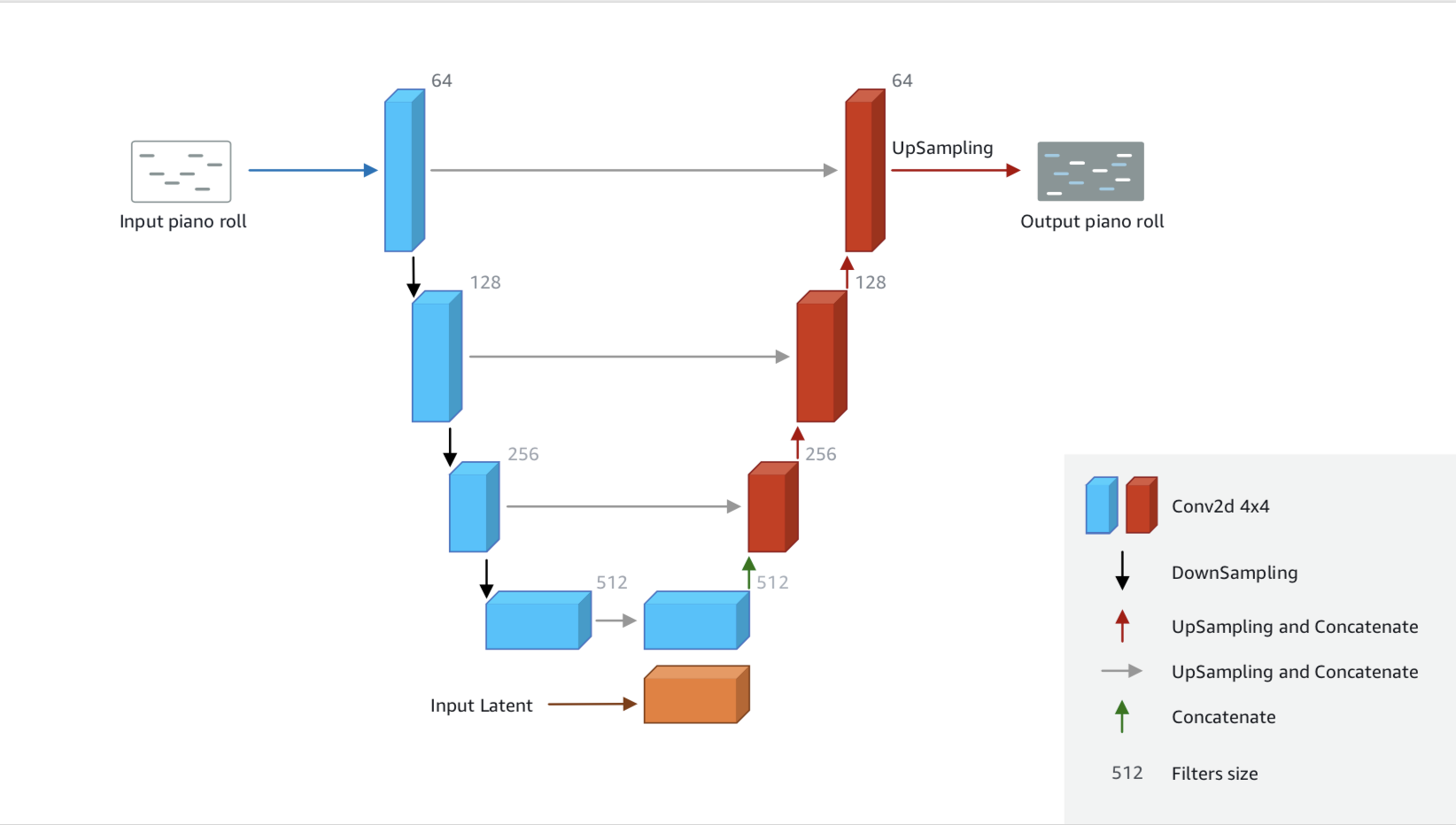
Generator
The generator network used in AWS DeepComposer is adapted from the U-Net architecture, a popular convolutional neural network that is used extensively in the computer vision domain. The network consists of an “encoder” that maps the single track music data (represented as piano roll images) to a relatively lower dimensional “latent space“ and a ”decoder“ that maps the latent space back to multi-track music data.
Here are the inputs provided to the generator:
- Single-track piano roll: A single melody track is provided as the input to the generator.
- Noise vector: A latent noise vector is also passed in as an input and this is responsible for ensuring that there is a flavor to each output generated by the generator, even when the same input is provided.
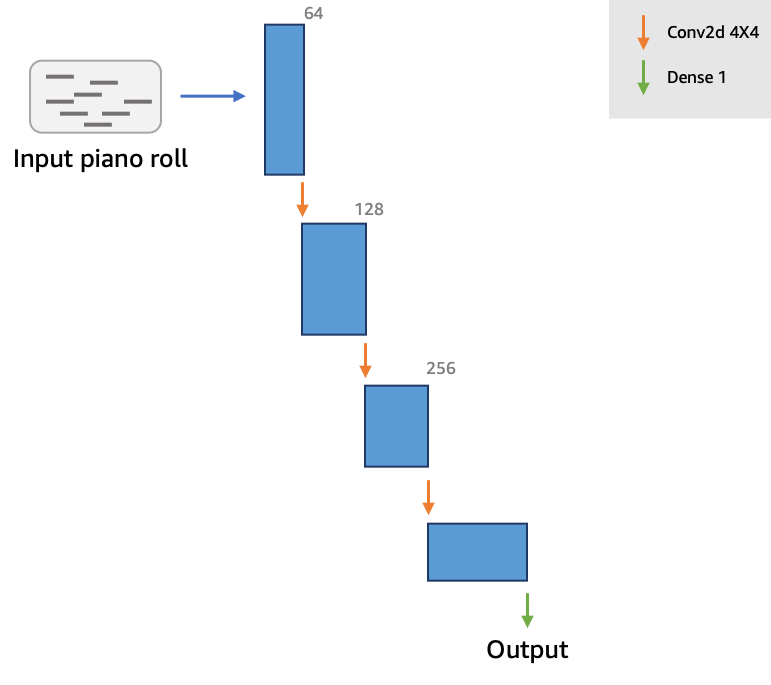
Discriminator
The goal of the discriminator is to provide feedback to the generator about how realistic the generated piano rolls are, so that the generator can learn to produce more realistic data. The discriminator provides this feedback by outputting a scalar value that represents how “real” or “fake” a piano roll is.
Since the discriminator tries to classify data as “real” or “fake”, it is not very different from commonly used binary classifiers. We use a simple architecture for the critic, composed of four convolutional layers and a dense layer at the end.
Evaluation
To address this, we take high-level measurements of our data and show how well our model produces music that aligns with those measurements. If our model produces music which is close to the mean value of these measurements for our training dataset, our music should match the general “shape”. You’ll see graphs of these measurements within the AWS DeepComposer console
Here are a few such measurements:
- Empty bar rate: The ratio of empty bars to total number of bars.
- Number of pitches used: A metric that captures the distribution and position of pitches.
- In Scale Ratio: Ratio of the number of notes that are in the key of C, which is a common key found in music, to the total number of notes.
Inference
Once this model is trained, the generator network alone can be run to generate new accompaniments for a given input melody. If you recall, the model took as input a single-track piano roll representing melody and a noise vector to help generate varied output.
The final process for music generation then is as follows:
- Transform single-track music input into piano roll format.
- Create a series of random numbers to represent the random noise vector.
- Pass these as input to our trained generator model, producing a series of output piano rolls. Each output piano roll represents some instrument in the composition.
- Transform the series of piano rolls back into a common music format (MIDI), assigning an instrument for each track.