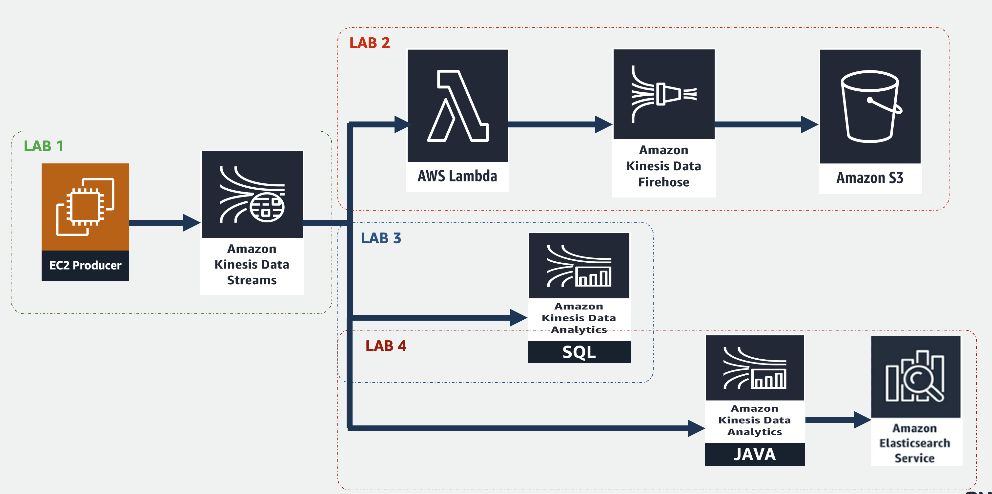
Notes from the workshops of building a streaming data platform on AWS.
Speed is definitely a key characteristic businesses are looking to have for a competitive edge in today’s world. Consumers increasingly want experiences that are timely, targeted, and tailored to their specific needs, whether they are applying for a loan, investing, checking health alerts, online shopping , tracking home security alerts, or monitoring systems.
Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data so you can get timely insights and react quickly to new information. It is fully managed, scalable, real-time streaming data process platfrom. It provides the following services:
Kinesis Data Streams
This is similar to Apache Kafka, providing low lantency streaming ingestion at scale. The message bus makes producers and consumers decoupled to generate the data and to read the data irrespectively. By default, the messages are retained for 24 hours. We can use any streaming process framework to consume the data, i.e. Spark Streaming or Apache Flink on EMR. Recently AWS Glue was added a new feature to support steaming ETL.
The core concept here is topic and shard. Topic is the name of a specific stream of data. Shard defines the capacity of reading and writing to the stream concurrently. Number of shards is required to manually configured to suite the throughput of the streaming data. This is similar to partition in Apache Kafka.
Kinesis Data Firehose
It can deliever the stream data to a certain AWS services like S3, RedShift, Elastic Search and Splunk. The source data can be Kinesis Data Streams. The more common use case is Lambda function is invoked once new data arrives in KDS. The data is processed by the Lambda function and then sent to Kinesis Data Firehose which is configured with a specific detination. KDF can specify the file format as well, for example, save as parquet files in S3 buckets.
Kinesis Data Analytics
It provides the easy way to analyze streaming data, gain actionable insights, and respond to your business and customer needs in real time. We can create Kinesis Data Analytics for SQL Applications, write SQL code and do schema transformation, or even do complex data analysis using inbuilt Machine learning feature.
We can also deploy Apache Flink application (supported Java or Scala) in Kinesis Data Analytics to process the streaming data. KDA will manage the underlying infrastruture and cluster used by Apache Flink, including provisioning compute resources, parallel processing, auto-scaling, and application backups. We just need to pay what we use.