Apache Spark is one of the most popular computational frameworks in the world of big data. Spark provides different programming language interfaces, a rich set of APIs for batch and streaming processing, as well as machine learning tasks. However, it is required a lot of efforts to optimise and tune Spark applications in order to utilise the resource of the cluster and run efficiently.
Here are some of the techniques I have employed when building Spark applications for various projects.
Providing a schema
Spark DataFrameReader supports a variety of different formats (i.e. JSON, CSV, Parquet, ORC, Avro) when reading the data sources into DataFrame. When the file format is JSON or CSV, it is a good practice to provide a schema so that Spark doesn’t need to cost extra resource to infer the schema especially when they are large files. When the source format is Parquet, we don’t need to provide the schema because it is defined in the metadata.
Reading the necessity
If partition key is defined in the schema of data source, we should take advantage of this to only read the data required to process. For example, if we need to process the log data for the past week, we can pass the filter to DataFrame so that Spark knows to apply a PartitionFiler to read those partitions only. If the data source is Parquet format, it is a good practice to specify the columns required for the job. Spark will utilise the columnar pushdown benefits of Parquet to avoid scan all the files.
Maximising pallarellism
One of the reasons that Spark is the de-facto data processing framework is that Spark brings the best of both worlds: we can run interactive SQL query as an enterprise data warehouse, while we can have the scalability as Hive/MapReduce.
Before we touch on Spark pallarellism, we need to be clear of some concepts. Normally a Spark job can be considered as one action. Job consists with one or many stages. One stage has one or many transformations before shuffle. One stage consists with tasks which is executing and utilising the hardware. Each task is the same but just working on different part of the data. Only tasks are interacting with the hardware.
Tasks = Slots = Cores, 1 task 1 partition 1 slot 1 core.
Bear with the above in mind, let us see what we can do to optimise resource utilisation and maximise parallelism.
- We should set at least as many partitions as there are cores on the executors. Rule of thumb is 2 * number of cores of the cluster.
- During input, the number of partitions is dictated by
spark.sql.files.maxPartitionBytes(default is 128MB). We can reduce this to increase the number of partitions. - Explicitly specify a certain number of partitions with
repartitionmethod. - During the shuffle stage, set
spark.sql.shuffle.partitionsto the desired number. - Through Spark UI, if Shuffle Spill (both memory and disk) is observed, it is an indication that we need to increase the number of partitions.
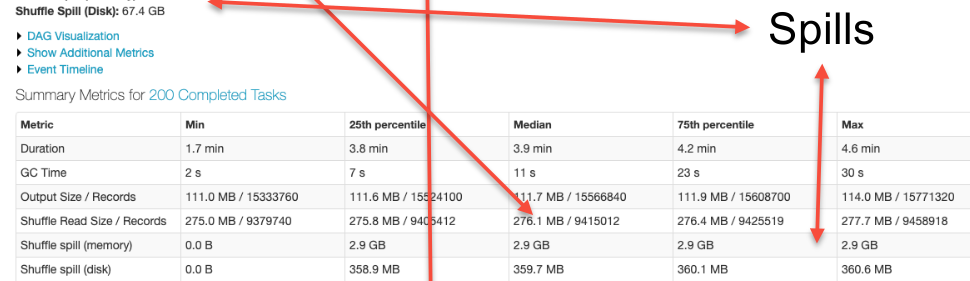
Minimising shuffle
Shuffle stage is created during operations like groupBy(), join() or windowing function. it is required to send data across the network to the executors’ task. It is expensive by consuming both network and disk I/O resources. That is why we must avoid any unnecessary data to be shuffled.
Below two DAGs are producing the same results. However, when we look into the shuffle data size, it is a huge difference. The diagram on the left is incurred much more time to run due to the large amount of data shuffle. So it is a good practice we inspect the SQL we write to check if any steps we can minimise the shuffle data size.
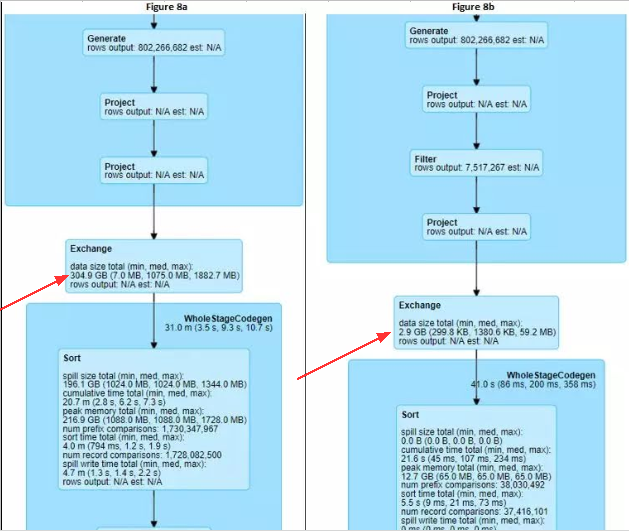
Caching the data
If a DataFrame is frequently accessed, it is a good idea to store the data in memory for better performance. Spark provides such capability with two API calls, cache() and persist().
Using proper join types
By default, Spark uses Sort Merge Join to combine two data sets based on matching common keys. It invokes a sort phrase and then an exchange phrase to move the data with the same key to the same partition.
If we know one data set is small, i.e. can fit in the driver’s and executor’s memory, we can use broadcast hash join instead which is the fastest way to avoid large amount of data movement. It is just simply to add broadcast() to the DataFrame when calling join().
Setting up a just fit cluster
One of the great advantages of cloud is that we can request the computational and storage resources whenever we need with the appropriate capacity, and just pay for what is used. AWS EMR or GCP Dataproc are the services which allow to spin up a cluster within a few minutes.
Imagine we need to process logs flowing in every hour with various sizes. We can create an ephemeral cluster which is tailored to the specific Spark job, and turn it down when the job is done. Based on the size of log files, we can define the just fit configuration, such as the number of executors, executor memory, number of partitions, etc. The end result is, we can guarantee the processing job is finished roughly at the same time, no matter the size is 5GB or 25GB.